InfiGUIAgent: A Multimodal Generalist GUI Agent with Native Reasoning and Reflection
ABSTRACT
InfiGUIAgent is an MLLM-based GUI Agent trained with a two-stage supervised fine-tuning pipeline. Stage 1 enhances fundamental skills such as GUI understanding and grounding, while Stage 2 integrates hierarchical reasoning and expectation-reflection reasoning skills using synthesized data to enable native reasoning abilities of the agents. InfiGUIAgent achieves competitive performance on several GUI benchmarks, highlighting the impact of native reasoning skills in enhancing GUI interaction for automation tasks.
Abstract
Graphical User Interface (GUI) Agents, powered by multimodal large language models (MLLMs), have shown great potential for task automation on computing devices such as computers and mobile phones. However, existing agents face challenges in multi-step reasoning and reliance on textual annotations, limiting their effectiveness. We introduce InfiGUIAgent, an MLLM-based GUI Agent trained with a two-stage supervised fine-tuning pipeline. Stage 1 enhances fundamental skills such as GUI understanding and grounding, while Stage 2 integrates hierarchical reasoning and expectation-reflection reasoning skills using synthesized data to enable native reasoning abilities of the agents. InfiGUIAgent achieves competitive performance on several GUI benchmarks, highlighting the impact of native reasoning skills in enhancing GUI interaction for automation tasks. Resources are available at https://github.com/Reallm-Labs/InfiGUIAgent.
Introduction
Graphical User Interface (GUI) Agents have emerged as powerful tools for automating tasks on computing devices, including mobile phones and computers. These agents can understand and interact with GUIs to execute complex operations, significantly enhancing user productivity and expanding the scope of automated task completion.
Recent developments in multimodal large language models (MLLMs) have significantly advanced the potential of GUI Agents. MLLMs possess powerful visual understanding capabilities and can reason based on visual information, making them a promising foundation for building sophisticated GUI Agents. These models can interpret complex interface elements and adapt to a wide range of tasks, leading to more efficient and robust automation.
However, current MLLM-based GUI Agents face several critical challenges. A key limitation lies in their reasoning capabilities. While many existing GUI Agents can perform basic single-step reasoning, they struggle to effectively leverage information from previous steps. This lack of reflection on past experiences can lead to repetitive errors during task execution.
Another significant challenge lies in the reliance on the additional information of the GUIs. Many prior GUI Agent implementations rely on accessibility trees or Set-of-Marks, to represent or augment the GUI's visual information. However, GUIs are inherently visual, and representing them primarily through text can lead to information loss or redundancy. Augmenting visual input with textual descriptions can also increase computational overhead. Furthermore, the availability and consistency of these textual representations vary across platforms, hindering practical deployment.
To address these limitations, we propose InfiGUIAgent, which is a MLLM-based GUI Agent trained through a two-stage supervised fine-tuning (SFT) methods with robust fundamental capabilities and native reasoning abilities. In stage 1, we collect data covering multiple tasks, such as vision-language understanding, GUI-specific QA, and tool use to improve fundamental capabilities such as GUI understanding and instruction grounding of the agents. In stage 2, we recognized two essential reasoning skills for GUI Agents: (1) Hierarchical reasoning, and (2) Expectation-reflection reasoning, and integrate these skills into the SFT data synthesized by MLLMs based on existing trajectories. Our main contributions are threefold:
- We propose a two-stage supervised fine-tuning pipeline to comprehensively improve both the fundamental abilities and advanced reasoning abilities of GUI Agents.
- We synthesize SFT data with two advanced reasoning skills: hierarchical reasoning and expectation-reflection reasoning, enabling the agents to natively perform complex reasoning.
- We build InfiGUIAgent by supervised fine-tuning a model using our SFT data and conduct experiments on several GUI benchmarks, demonstrating that our model achieves competitive performance.
Related Works
Multimodal LLMs
Large Language Models (LLMs) have significantly enhanced the capabilities of AI systems in tackling a wide range of tasks, thanks to their exceptional ability to process complex semantic and contextual information. The remarkable power of LLMs has also inspired exploration into their potential for processing multimodal data, such as images. Typically, the architecture of Multimodal Large Language Models (MLLMs) consists of three main components: a pre-trained large language model, a trained modality encoder, and a modality interface that connects the LLM with the encoded modality features. Various vision encoders, such as ViT, CLIP, and ConvNeXt, extract visual features, which are integrated using techniques like adapter networks, cross-attention layers, and visual expert modules. These methods have facilitated the development of high-performing MLLMs, such as Qwen-VL, GPT-4 Vision, BLIP-2 and InfiMM, thus opening new avenues for LLMs in processing GUI tasks.
MLLM-based GUI Agents
Agents are AI systems that perceive their environments, make decisions, and take actions to complete specific tasks. LLMs reaching human-level intelligence have greatly enhanced the ability to build agents. For GUI tasks, LLMs that read HTML code to perceive GUIs are developed. However, various works have shown that learning to interact with the visual form of the GUIs can show superior performance. Therefore, MLLM-based GUI Agents are developed. ILuvUI fine-tuned LLaVA to enhance general GUI understanding, while AppAgent explored app usage through autonomous interactions. CogAgent integrated high-resolution vision encoders, and Ferret-UI-anyres employed an any-resolution approach. Building upon these works, our study focuses on developing a more lightweight agent with a simplified architecture for GUI tasks, aiming to improve ease of deployment.
Method
In this section, we introduce our two-stage supervised fine-tuning strategy for building InfiGUIAgent. In stage 1, we focus on improving fundamental abilities such as understanding and grounding, particularly considering the complexity of GUIs. In stage 2, we move on to improve the native reasoning abilities of agents for handling complicated GUI tasks.
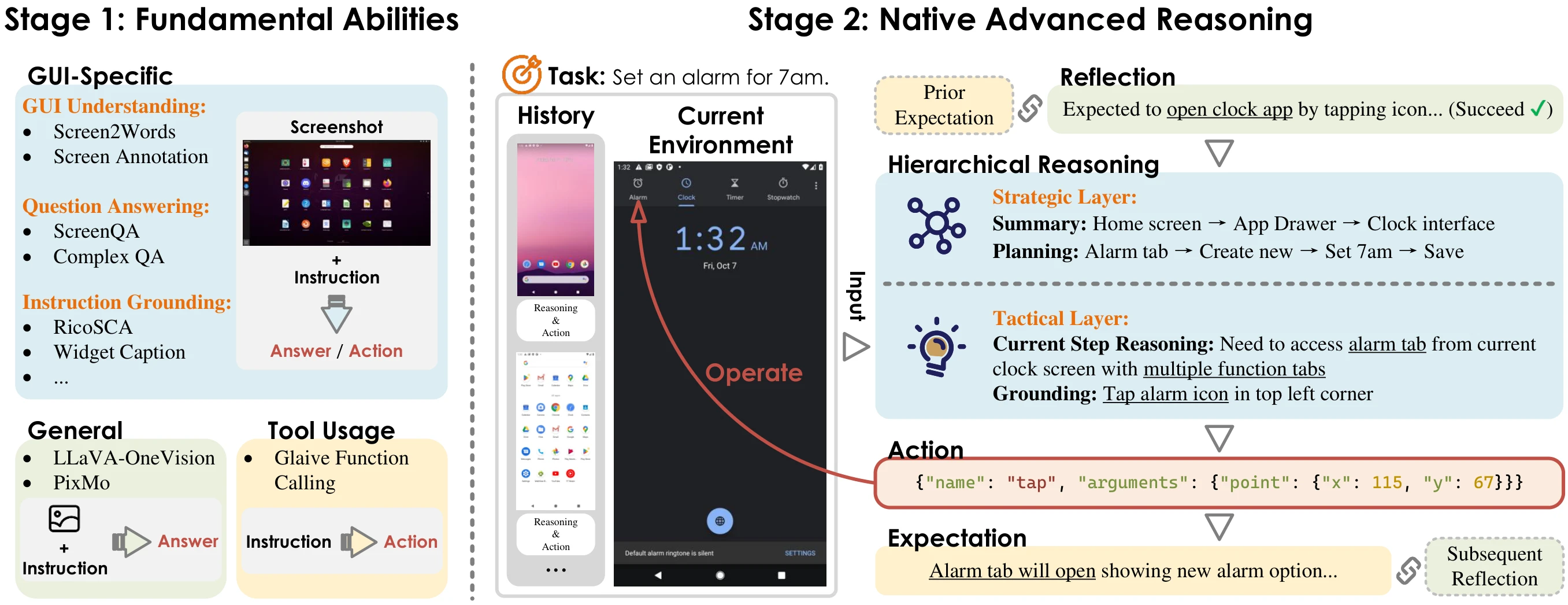
InfiGUIAgent is trained in two stages. Stage 1 cultivates fundamental abilities using diverse datasets covering GUI understanding (element recognition and layout comprehension), question answering, instruction grounding, general knowledge, and tool usage. Stage 2 introduces native advanced reasoning, employed during both training and inference. This stage follows a cyclical process at each step, consisting of Reflection, Hierarchical Reasoning (strategic and tactical layers), Action, and Expectation. Each step receives the overall task, the history of previous screenshots and reasoning, and the current environment as input. Reflection assesses the previous action's outcome against its expectation, while Expectation predicts the outcome of the current action for subsequent reflection.
Stage 1: Training for Fundamental Abilities
Considering the complexity of GUIs, which involve diverse data formats such as HTML code, high-resolution interfaces cluttered with small icons and text, general MLLMs lack fundamental abilities in both understanding GUI and grounding the actions. To address this, we first collected a range of existing visual-language and GUI datasets for supervised fine-tuning in stage 1. We gathered data covering several GUI tasks from multiple sources to ensure a comprehensive capabilities improvement. The datasets can be categorized into five parts:
- GUI Understanding. Datasets focusing on GUI element recognition, layout comprehension, and semantic interpretation, including Screen2Words and Screen Annotation.
- Grounding. Datasets capture various user interaction sequences and operation patterns, including GUIEnv, RICO Semantic Annotation, SeeClick-Web, RICO SCA, Widget Caption, UIBert Reference Expression and OmniAct-Single Click.
- Question Answering. Datasets contain GUI-specific QA tasks, including GUIChat, ScreenQA and Complex QA.
- General Knowledge. Multimodal datasets maintain model's general capabilities, including LLaVA-OneVision and PixMo.
- Tool Usage. Datasets cover general tool using, including Glaive-function-calling.
Stage 1 Training Datasets:
| Dataset | Platform | Category | # of Samples |
|---|---|---|---|
| GUI-related Datasets | |||
| GUIEnv | Webpage | Grounding | 150,000 |
| RICO Semantic Annotation | Mobile | Grounding | 150,000 |
| SeeClick-Web | Webpage | Grounding | 100,000 |
| RICO SCA | Mobile | Grounding | 100,000 |
| Widget Caption | Mobile | Grounding | 70,000 |
| GUIChat | Webpage | QA | 40,000 |
| ScreenQA | Mobile | QA | 17,000 |
| UIBert Reference Expression | Mobile & Mobile | Grounding | 16,000 |
| Screen2Words | Mobile | Understanding | 12,000 |
| Complex QA | Mobile | QA | 11,000 |
| Screen Annotation | Mobile | Understanding | 5,400 |
| OmniAct-Single Click | Webpage & Desktop | Grounding | 4,800 |
| Non-GUI Datasets | |||
| LLaVA-OneVision | - | General | 250,000 |
| PixMo | - | General | 68,800 |
| Glaive-function-calling | - | Tool Usage | 5,000 |
Due to the diversity of our data sources, we implemented comprehensive format standardization across all datasets. Additionally, we adopted the Reference-Augmented Annotation format to enhance the model's ability to ground visual elements with textual descriptions, enabling precise spatial referencing while maintaining natural language flow.
Data Preprocessing and Standardization
Given the diversity of our data sources, we implemented comprehensive preprocessing steps to standardize the data format across all datasets. We normalized the coordinate system by following Qwen2-VL, mapping all spatial coordinates to a relative scale of [0, 1000]. This standardization facilitates consistent representation of both point and box annotations in JSON format, with points expressed as and bounding boxes as . In this coordinate system, the origin is located at the screen's top-left corner, with the x-axis extending rightward and the y-axis downward. The bottom-right corner corresponds to coordinates .
To enhance data quality, we implemented two additional preprocessing steps:
- Instruction Enhancement. For datasets with ambiguous instructions, we developed standardized instruction templates to establish clear correspondence between commands and their expected outcomes.
- Response Refinement. For entries with complex or inconsistent response formats, we utilized Qwen2-VL-72B to reformulate responses while preserving their semantic content. Each reformulation underwent validation to ensure accuracy and consistency.
Reference-Augmented Annotation
To better leverage the spatial information available in our collected datasets and enhance the model's visual-language understanding of GUIs, we implemented a reference-augmented annotation format. This format enables bidirectional referencing between GUI elements and textual responses. Specifically, we adopted the following structured notation:

The format consists of several key components: the reference type (either "box" for rectangular regions or "point" for specific locations), coordinate specifications (x1, y1, x2, y2 for boxes or x, y for points), optional annotative notes, and the corresponding textual content. To generate training data in this format, we prompted Qwen2-VL-72B to seamlessly integrate GUI spatial information with original responses, maintaining natural language flow while preserving precise spatial references.
Stage 2: Training for Native Reasoning
Building upon the foundational capabilities such as understanding and grounding, GUI Agents must also master advanced reasoning skills to effectively handle complex tasks. We identify two crucial reasoning skills:
- Hierarchical reasoning, which enables planning and task decomposition, helping agents structure complex tasks into manageable subtasks and execute them efficiently.
- Expectation-reflection reasoning, which fosters adaptive self-correction and reflection, enabling agents to learn from past actions and improve decision-making consistency.
These reasoning skills are integrated into the training datasets of agents, so that they can reason with these skills natively without any extra prompting. To achieve this, we generate SFT data incorporating these reasoning skills based on existing trajectory data and continue fine-tuning the model from stage 1.
Stage 2 Training Datasets:
| Dataset | Platform | # of Samples |
|---|---|---|
| GUIAct | Webpage & Mobile | 10,000 |
| AMEX | Mobile | 3,000 |
| Android in the Zoo | Mobile | 2,000 |
| Composition: Stage 1-aligned | - | 30,000 |
Hierarchical Reasoning
Effective execution of GUI tasks demands both overarching strategic planning and meticulous tactical execution. To achieve this, we synthesize trajectory data with a hierarchical reasoning with two distinct layers:
- Strategic Layer. Strategic layer is responsible for high-level task decomposition and sub-goal planning. This layer analyzes the overall task objective and determines the sequence of subtasks needed for completion.
- Tactical Layer. Tactical layer handles the selection and grounding of concrete actions. Based on the strategic layer's planning, agent select appropriate GUI operations and adjusts their parameters to match the target.
Expectation-Reflection Reasoning
To enhance action consistency and foster autonomous self-correction, we incorporate Expectation-reflection reasoning into the training datasets. This iterative process enhances the agent's ability to adapt and learn from its actions through a structured reflection cycle:
- Reasoning. After reflection (except the first step), the agents conduct hierarchical reasoning.
- Action. After the reasoning, the agent takes the action.
- Expectation. Following each action, the agent generates expected outcomes which are used to be verified at the next step.
- Reflection. The agent evaluates whether its actions achieved the expected results and generating a textual summary of the reflection.
Agent-Environment Interface
We formulate the GUI interaction as a process where an agent interacts with a mobile environment. Let denote the environment state at step , where represents the state space. The agent can observe the state through a screenshot observation and performs actions , where is the action space. The environment transitions from to following , where represents the transition probability function.
The agent receives a task goal and maintains access to a history window of size . At each step , the agent's input consists of:
- Goal
- Current observation
- Historical context , where represents the reasoning process
Based on these inputs, the agent generates a reasoning process and predicts an action . The interaction follows a standard protocol using function calls and responses:

Modular Action Space
Given the diverse action spaces across collected datasets, we categorized and standardized the actions by unifying their names and parameters, merging similar operations where appropriate. The resulting action space consists of independent, composable operations that can be flexibly combined based on task requirements:
| Category | Operations |
|---|---|
| Single-point operations | tap, click, hover, select |
| Two-point operations | swipe, select_text |
| Directional operations | scroll |
| Text input | input, point_input |
| Parameterless operations | remember, enter, home, back |
| State settings | set_task_status |
This modular design allows for dynamic action space configuration while maintaining a consistent interface across different platforms and scenarios.
Reasoning Process Construction
To construct high-quality reasoning data to stimulate the model's native reasoning capabilities, we leverage more capable MLLMs (e.g. Qwen2-VL-72B) to generate structured reasoning processes based on existing interaction trajectories. The construction process involves several key components:
- Screenshot Description. For each observation in the trajectory, we generate a detailed description . This step addresses the limitation that some MLLM models do not support interleaved image-text input formats well. To establish clear correspondence between observations (screenshots) and steps, we generate detailed descriptions to replace the screenshots, which helps facilitate the subsequent reasoning process construction.
- Reflection. Given the previous expectation and current observation , we generate a reflection that evaluates the outcome of the previous action.
- Strategic Layer. The strategic reasoning consists of two parts: First, a summary is generated based on the n-step history and current observation . Then, the planning component is generated with access to the actual action to ensure alignment with the trajectory.
- Tactical Layer. This layer's reasoning is constructed using the generated reflection and strategic layer output. The actual action from the trajectory is incorporated to ensure the tactical reasoning leads to appropriate action selection.
- Expectation. For each state-action pair , we generate an expectation based on current observation , reasoning process , and action . Notably, we deliberately avoid using the next state in this generation process. Although using could improve the agent's accuracy in modeling state transitions, while using could lead to perfect expectations, such an approach might impair the agent's ability to handle expectation mismatches during deployment.
While we avoid using in expectation generation to maintain robustness, we also explore the possibility of improving state transition modeling through a parallel next-state prediction task. Using the trajectory data, we construct additional training examples where the agent learns to predict the next state description given the current observation and action . This auxiliary task helps the agent learn state transition dynamics, while keeping the expectation generation process independent of future states.
Experiments
Experimental Setting
Implementation Details
In stage 1, we sample 1M samples in total. In stage 2, we synthesized 45K samples based on trajectories from the datasets listed above. We continual supervised fine-tune Qwen2-VL-2B. We leverage ZeRO0 technology to enable full parameter fine-tuning of the model across 8 A800 80GB GPUs.
Evaluation Benchmarks
ScreenSpot. ScreenSpot is an evaluation benchmark for GUI grounding, consisting of over 1,200 instructions from iOS, Android, macOS, Windows, and Web environments, with annotated element types.
AndroidWorld. AndroidWorld is a fully functional Android environment that provides reward signals for 116 programmatic tasks across 20 real-world Android apps. We find that Android World uses Set-of-Marks (SoM) to enhance the agent's grounding ability. However, when humans operate smartphones, their brains do not label elements on the screen. Over-reliance on SoM can lead to insufficient focus on pixel-level grounding ability. Therefore, in our experiments, agents respond to the raw image rather than the annotated image.
Main Results
ScreenSpot
| Model | Mobile Text | Mobile Icon | Desktop Text | Desktop Icon | Web Text | Web Icon | Avg. |
|---|---|---|---|---|---|---|---|
| Proprietary Models | |||||||
| GPT-4o | 30.5 | 23.2 | 20.6 | 19.4 | 11.1 | 7.8 | 18.8 |
| Gemini-1.5-pro | 76.2 | 54.1 | 65.5 | 39.3 | 52.2 | 32.0 | 53.2 |
| Open-source Models | |||||||
| Qwen2-VL-2B | 24.2 | 10.0 | 1.4 | 9.3 | 8.7 | 2.4 | 9.3 |
| Qwen2-VL-7B | 61.3 | 39.3 | 52.0 | 45.0 | 33.0 | 21.8 | 42.9 |
| CogAgent | 67.0 | 24.0 | 74.2 | 20.0 | 70.4 | 28.6 | 47.4 |
| SeeClick | 78.0 | 52.0 | 72.2 | 30.0 | 55.7 | 32.5 | 53.4 |
| UGround-7B | 82.8 | 60.3 | 82.5 | 63.6 | 80.4 | 70.4 | 73.3 |
| ShowUI-2B | 92.3 | 75.5 | 76.3 | 61.1 | 81.7 | 63.6 | 75.1 |
| Ours | |||||||
| InfiGUIAgent-2B | 88.6 | 74.7 | 85.6 | 65.0 | 79.1 | 64.6 | 76.3 |
The following table provides the results of different models across three platforms (Mobile, Desktop and Web) and two element types (Text and Icon) on ScreenSpot. InfiGUIAgent-2B achieves highest accuracy of 76.3%, surpassing several strong baselines such as ShowUI (75.1%) and UGround-7B (73.3%), which is even with larger parameters size.
AndroidWorld
| Model | Easy | Middle | Hard | Overall |
|---|---|---|---|---|
| Qwen2-VL-2B | 0.00 | 0.00 | 0.00 | 0.00 |
| Qwen2-VL-7B | 0.00 | 0.00 | 0.05 | 0.05 |
| Qwen2-VL-72B | 0.08 | 0.00 | 0.05 | 0.05 |
| LLaVa-OV-7B | 0.00 | 0.00 | 0.00 | 0.00 |
| ShowUI-2B | 0.18 | 0.00 | 0.00 | 0.07 |
| Ours | ||||
| InfiGUIAgent-2B | 0.25 | 0.00 | 0.00 | 0.09 |
The following table compares the success rates of InfiGUIAgent with open-source models on AndroidWorld. InfiGUIAgent-2B achieves an overall success rate of 0.09, outperforming open-source models of similar size, such as ShowUI-2B (0.07), and model with much more parameters such as LLaVa-OV-7B (0.00) and Qwen2-VL-72B (0.05).
Appendix: Case Studies
Stage 1: Fundamental Abilities
We demonstrate the fundamental abilities trained in Stage 1 through three cases: GUI Understanding, Grounding, and Question Answering.
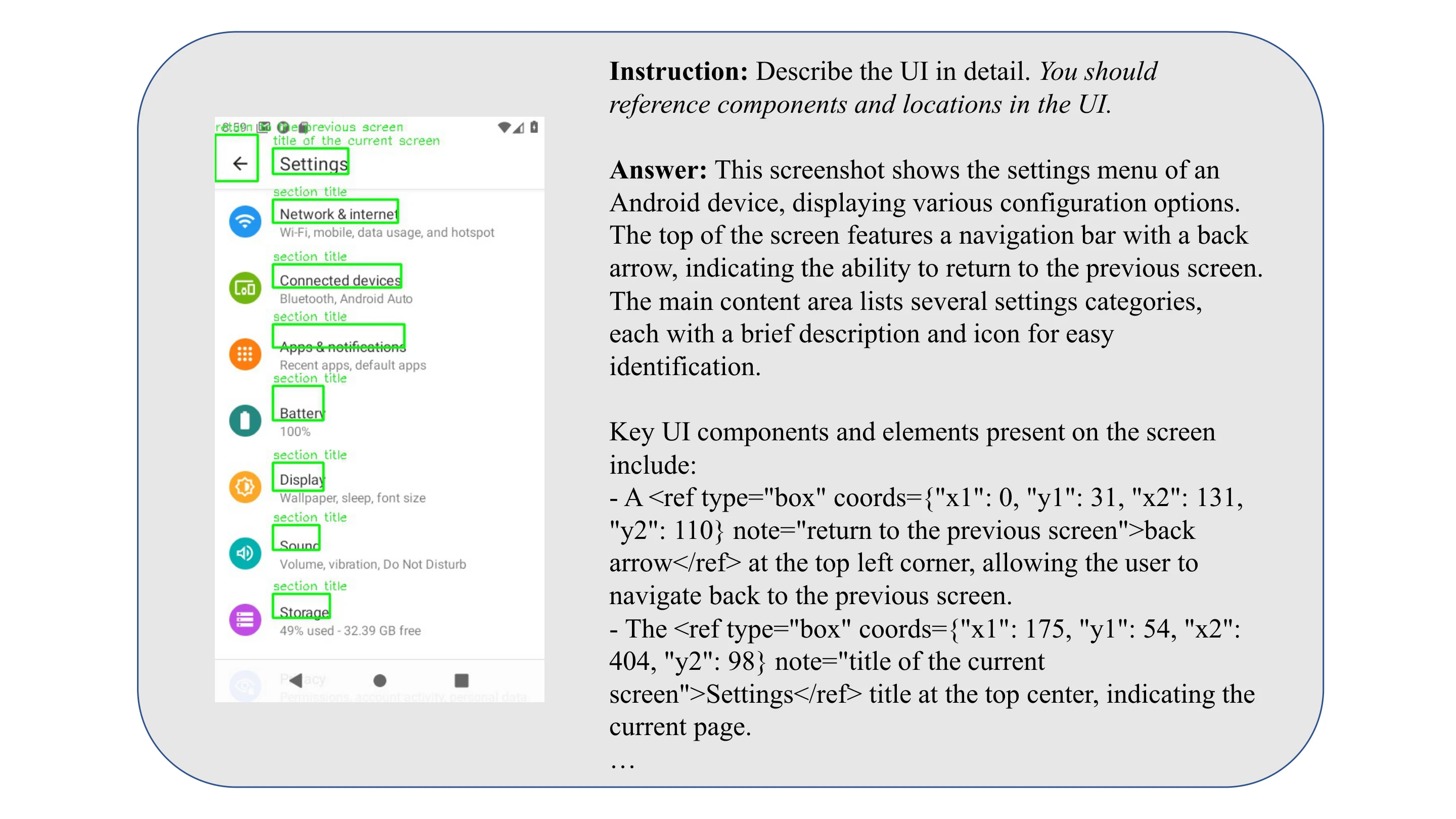
Case of GUI Understanding.

Case of Grounding.
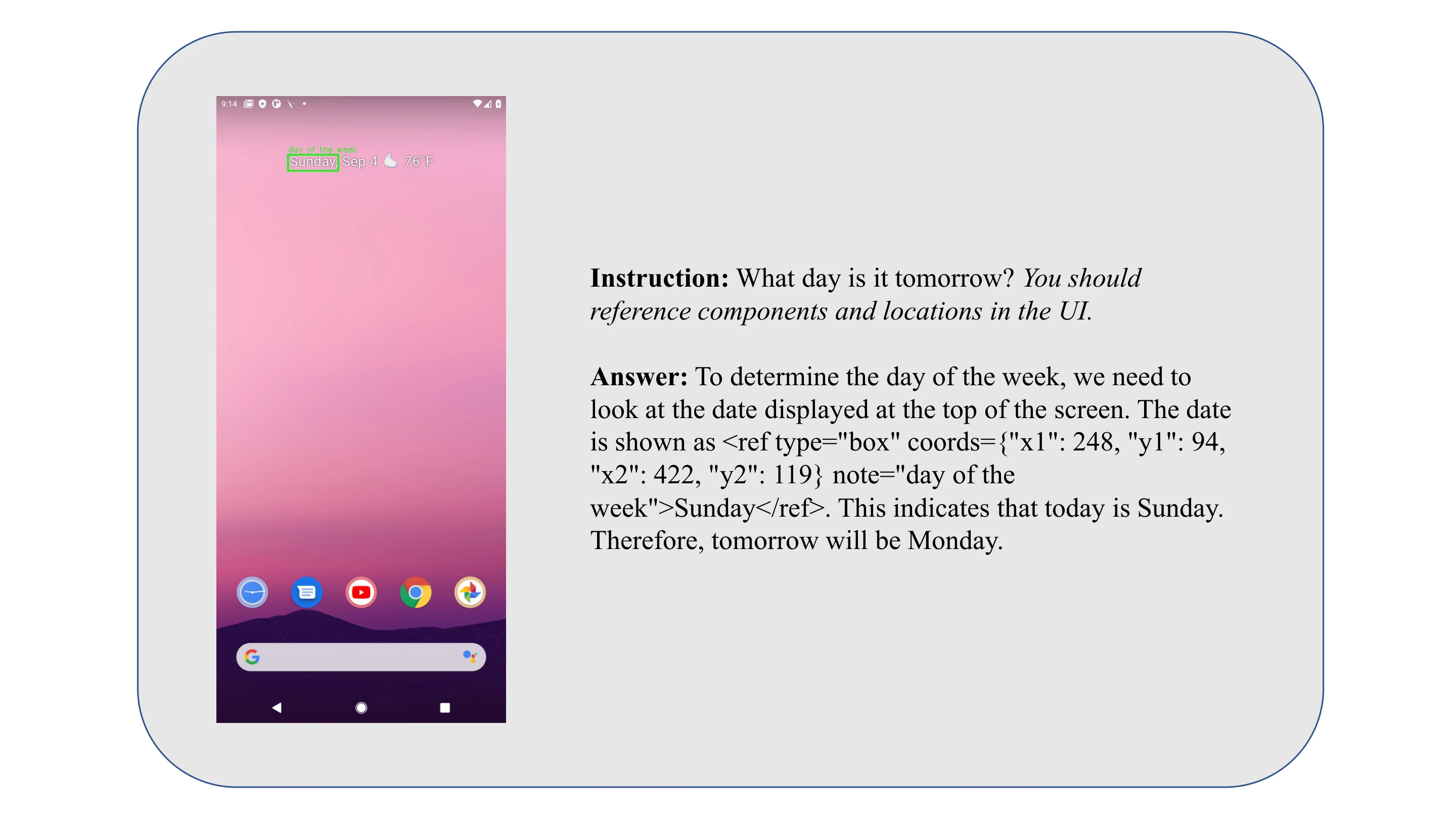
Case of Question Answering.
Stage 2: Native Reasoning
We provide two representative cases to demonstrate the reasoning and interaction process of InfiGUIAgent.
Reply to a Message. The following figure illustrates a step where the agent needs to reply to a specific message in a messaging application. The reasoning process involves identifying the "Start chat" button and grounding the action to initiate the reply process.
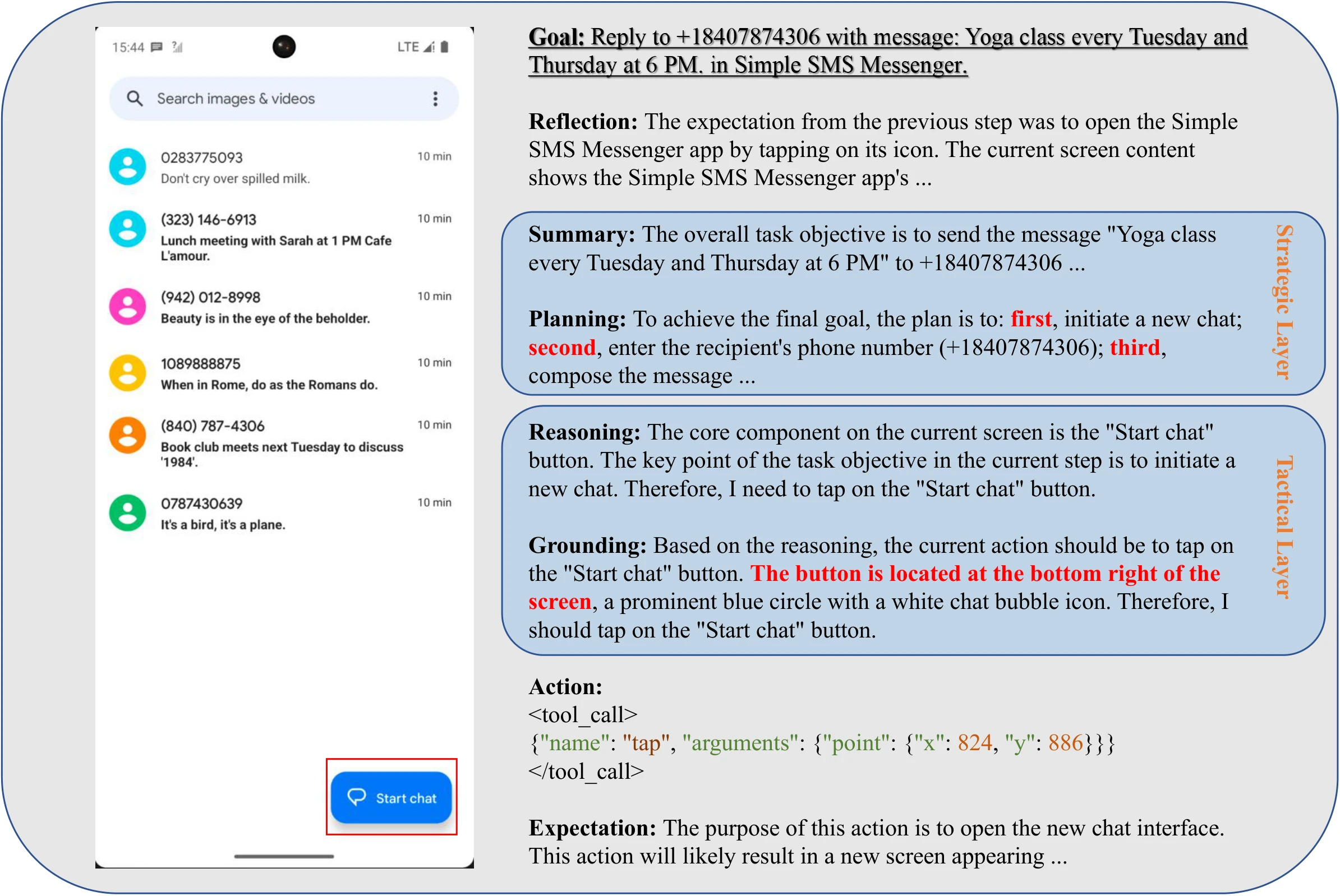
Case of Native Advanced Reasoning. The agent's goal is to reply to a message.
Creating a New Contact. The following figures demonstrate sequential steps for creating a new contact. In the first step (Step K), the agent navigates to the "Contacts" section by reasoning and grounding the action to the corresponding tab. In the following step (Step K+1), the agent initiates the contact creation process by identifying and tapping the "Create new contact" button. These sequential steps highlight the agent's hierarchical reasoning and grounding abilities.
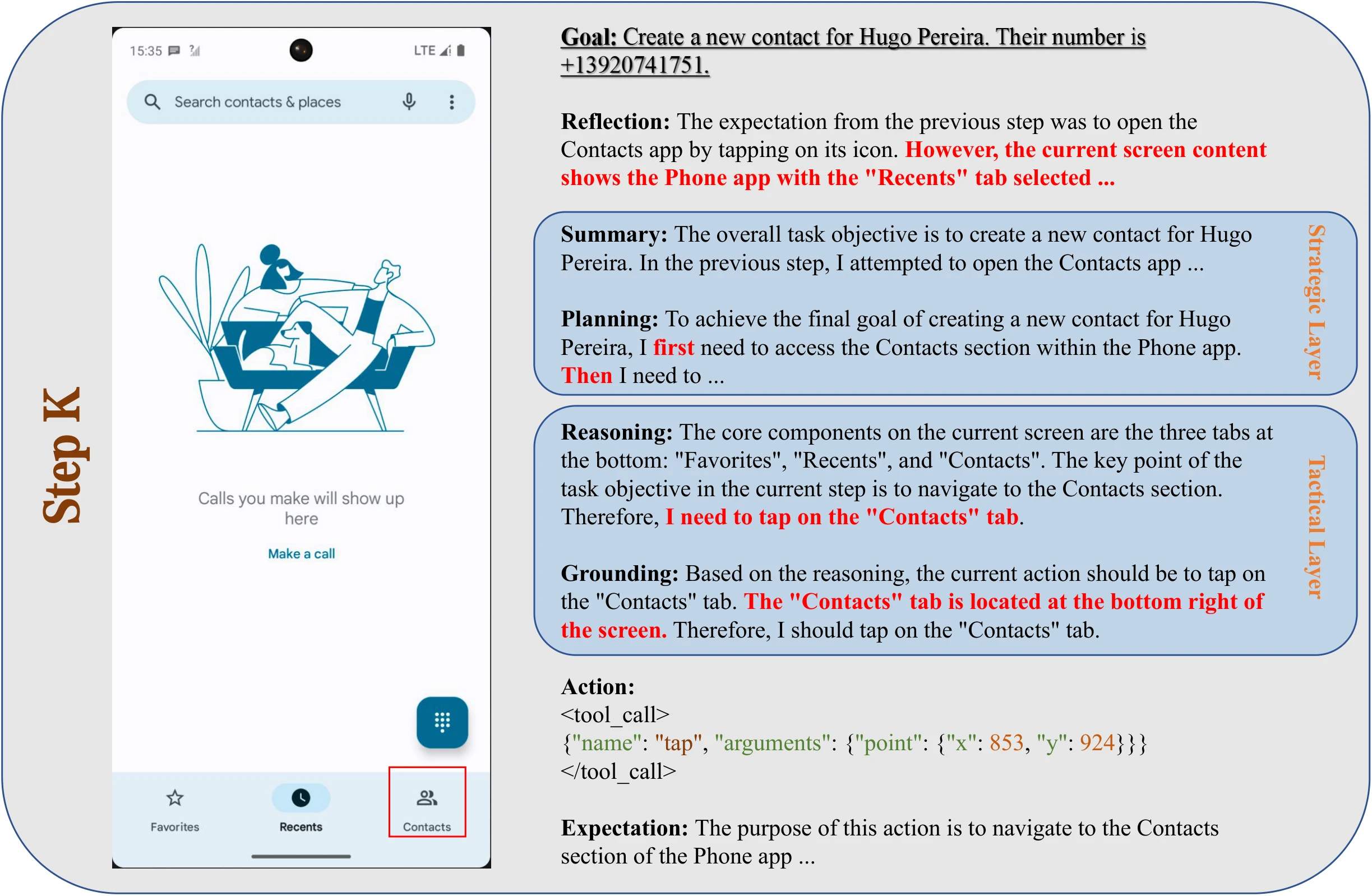
Case of Native Advanced Reasoning. The agent's goal is to create a new contact.
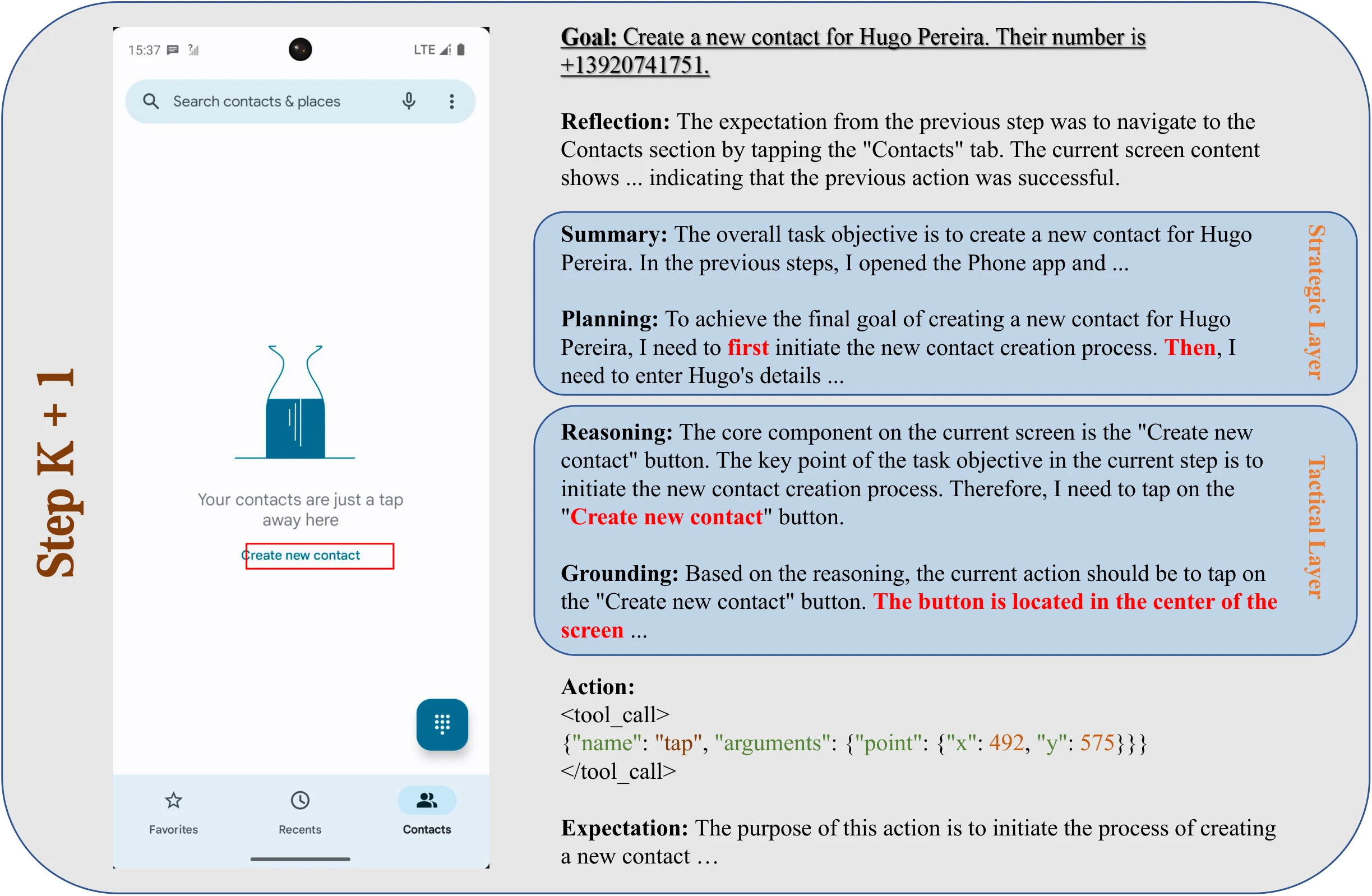
Case of Native Advanced Reasoning. The agent's goal is to create a new contact.
Conclusion
In this work, we propose InfiGUIAgent, a novel MLLM-based GUI Agents. By constructing comprehensive training datasets with two-stage supervised fine-tuning, we enhance the model's ability to understand, reason, and interact with GUIs. Our evaluation, conducted using raw screenshots without relying on additional GUI metadata, demonstrates the model's applicability to real-world scenarios. Experimental results show that our model performs well on GUI tasks and surpass several open-source baselines.
BibTeX
@article{liu2025infiguiagent,
title={InfiGUIAgent: A Multimodal Generalist GUI Agent with Native Reasoning and Reflection},
author={Liu, Yuhang and Li, Pengxiang and Wei, Zishu and Xie, Congkai and Hu, Xueyu and Xu, Xinchen and Zhang, Shengyu and Han, Xiaotian and Yang, Hongxia and Wu, Fei},
journal={arXiv preprint arXiv:2501.04575},
year={2025}
}