InfiR2-7B-Instruct-FP8
We performed supervised fine-tuning on the InfiR2-7B-base-FP8 with FP8 format in two stages using the InfiAlign-SFT-72k and InfiAlign-SFT-165k datasets.
We performed supervised fine-tuning on the InfiR2-7B-base-FP8 with FP8 format in two stages using the InfiAlign-SFT-72k and InfiAlign-SFT-165k datasets.
Training Recipe:
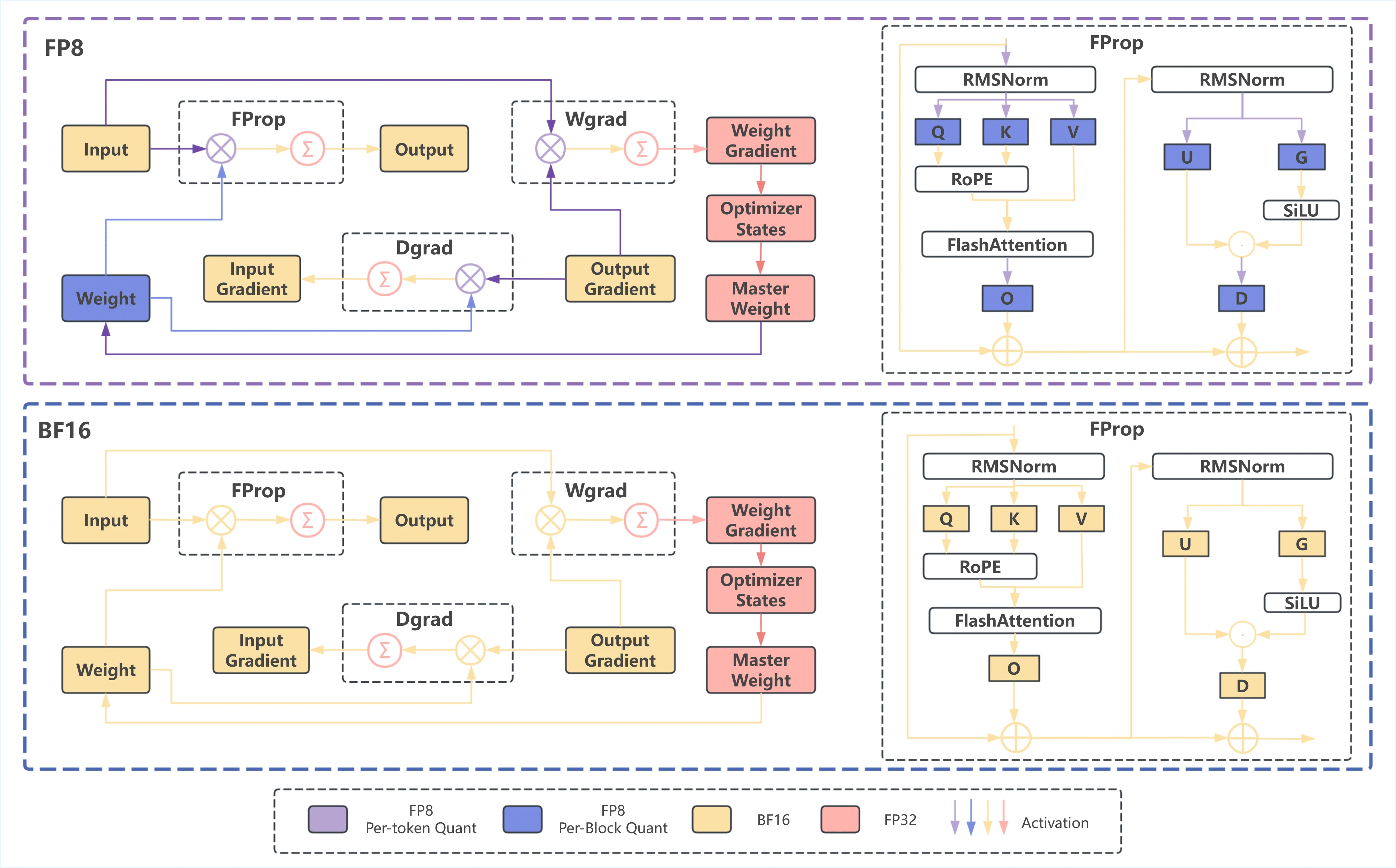
- Stable and Reproducible Performance
- Efficient and Low memory Training
Hyperparameters:
| Parameter | Value |
|---|---|
| Batch Size | 64 |
| Learning Rate | 1e-5 |
| Minimum Learning Rate | 1e-6 |
| Weight Decay | 0.05 |
| Context Length | 32k |
The resulting model is the InfiR2-7B-Instruct-FP8.
🚀 InfiR2 Model Series
The InfiR2 framework offers multiple variants model with different size and training strategy:
- 1.5B
- InfiR2-1.5B-base-FP8: Continue pretrain on Qwen2.5-1.5B-base
- InfiR2-1.5B-Instruct-FP8: Supervised fine-tuning on InfiR2-1.5B-base-FP8 with InfiAlign dataset
- 7B
- InfiR2-7B-base-FP8: Continue pretrain on Qwen2.5-7B-base
- InfiR2-7B-Instruct-FP8: Supervised fine-tuning on InfiR2-7B-base-FP8 with InfiAlign dataset
- InfiR2-R1-7B-FP8-Preview: Multi-stage FP8 Reinforcement Learning
📊 Model Performance
Below is the performance comparison of InfiR2-7B-Instruct-FP8 on reasoning benchmarks. Note: 'w. InfiAlign' denotes Supervised Fine-Tuning (SFT) using the InfiAlign dataset.
| Model | AIME 25 | AIME 24 | GPQA | LiveCodeBench v5 |
|---|---|---|---|---|
| Deepseek-Distill-Qwen-7B | 43.00 | 49.00 | 48.20 | 37.60 |
| Qwen2.5-7B-base (w. InfiAlign) | 33.75 | 43.02 | 48.11 | 39.48 |
| InfiR2-7B-Instruct-FP8 | 40.62 | 55.73 | 45.33 | 40.31 |
🎭 Quick Start
from vllm import LLM, SamplingParams
import torch
import os
MODEL_NAME = "InfiX-ai/InfiR2-7B-Instruct-FP8"
prompt_text = "Briefly explain what a black hole is, and provide two interesting facts."
MAX_NEW_TOKENS = 256
TEMPERATURE = 0.8
DO_SAMPLE = True
llm = LLM(
model=MODEL_NAME,
dtype="auto",
)
sampling_params = SamplingParams(
n=1,
temperature=TEMPERATURE,
max_tokens=MAX_NEW_TOKENS,
)
tokenizer = llm.get_tokenizer()
messages = [
{"role": "user", "content": prompt_text}
]
prompt_formatted = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(
prompt_formatted,
sampling_params
)
generated_text = outputs[0].outputs[0].text
llm_response = generated_text.strip()
print("\n" + "="*70)
print(f"Prompt: \n{prompt_text}")
print("-" * 70)
print(f"(LLM Response): \n{llm_response}")
print("="*70)
📚 Model Download
# Create a directory for models
mkdir -p ./models
# Download InfiR2-7B-Instruct-FP8 model
huggingface-cli download --resume-download InfiX-ai/InfiR2-7B-Instruct-FP8 --local-dir ./models/InfiR2-7B-Instruct-FP8
🎯 Intended Uses
✅ Direct Use
This model is intended for research and commercial use. Example use cases include:
- Instruction following
- Mathematical reasoning
- Code generation
- General reasoning
❌ Out-of-Scope Use
The model should not be used for:
- Generating harmful, offensive, or inappropriate content
- Creating misleading information
🙏 Acknowledgements
- We would like to express our gratitude for the following open-source projects: Slime, Megatron, TransformerEngine and Qwen2.5.
📌 Citation
If you find our work useful, please cite:
@misc{wang2025infir2comprehensivefp8training,
title={InfiR2: A Comprehensive FP8 Training Recipe for Reasoning-Enhanced Language Models},
author={Wenjun Wang and Shuo Cai and Congkai Xie and Mingfa Feng and Yiming Zhang and Zhen Li and Kejing Yang and Ming Li and Jiannong Cao and Hongxia Yang},
year={2025},
eprint={2509.22536},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2509.22536},
}