InfiGFusion: Graph-on-Logits Distillation via Efficient Gromov-Wasserstein for Model Fusion
ABSTRACT
Recent advances in large language models (LLMs) have intensified efforts to fuse heterogeneous open-source models into a unified system that inherits their complementary strengths. Existing logit-based fusion methods maintain inference efficiency but treat vocabulary dimensions independently, overlooking semantic dependencies encoded by cross-dimension interactions. These dependencies reflect how token types interact under a model's internal reasoning and are essential for aligning models with diverse generation behaviors. To explicitly model these dependencies, we propose InfiGFusion, the first structure-aware fusion framework with a novel Graph-on-Logits Distillation (GLD) loss. Specifically, we retain the top-k logits per output and aggregate their outer products across sequence positions to form a global co-activation graph, where nodes represent vocabulary channels and edges quantify their joint activations. To ensure scalability and efficiency, we design a sorting-based closed-form approximation that reduces the original O(n^4) cost of Gromov-Wasserstein distance to O(n log n), with provable approximation guarantees. Experiments across multiple fusion settings show that GLD consistently improves fusion quality and stability. InfiGFusion outperforms SOTA models and fusion baselines across 11 benchmarks spanning reasoning, coding, and mathematics. It shows particular strength in complex reasoning tasks, with +35.6 improvement on Multistep Arithmetic and +37.06 on Causal Judgement over SFT, demonstrating superior multi-step and relational inference.
Abstract
Recent advances in large language models (LLMs) have intensified efforts to fuse heterogeneous open-source models into a unified system that inherits their complementary strengths. Existing logit-based fusion methods maintain inference efficiency but treat vocabulary dimensions independently, overlooking semantic dependencies encoded by cross-dimension interactions. These dependencies reflect how token types interact under a model's internal reasoning and are essential for aligning models with diverse generation behaviors. To explicitly model these dependencies, we propose InfiGFusion, the first structure-aware fusion framework with a novel Graph-on-Logits Distillation (GLD) loss. Specifically, we retain the top- logits per output and aggregate their outer products across sequence positions to form a global co-activation graph, where nodes represent vocabulary channels and edges quantify their joint activations. To ensure scalability and efficiency, we design a sorting-based closed-form approximation that reduces the original cost of Gromov-Wasserstein distance to , with provable approximation guarantees. Experiments across multiple fusion settings show that GLD consistently improves fusion quality and stability. InfiGFusion outperforms SOTA models and fusion baselines across 11 benchmarks spanning reasoning, coding, and mathematics. It shows particular strength in complex reasoning tasks, with +35.6 improvement on Multistep Arithmetic and +37.06 on Causal Judgement over SFT, demonstrating superior multi-step and relational inference.
Introduction
Recent advances in LLMs have sparked growing interest in aggregating diverse model capabilities to build stronger, more general-purpose systems. Existing collective approaches span a broad design space. Prompt-based techniques dynamically chain or compose pretrained LLMs with tools or APIs to expand functional scope. Multi-agent systems employ multiple LLMs to collaborate or debate, often outperforming single-agent models on complex reasoning tasks. Model ensembling aggregates outputs from different models to boost accuracy and robustness, while Mixture-of-Experts (MoE) architectures improve scalability by activating specialized subnetworks. Meanwhile, parameter-level merging models aim to consolidate multiple fine-tuned checkpoints into a single model. Each of these paradigms explores a different trade-off between performance, efficiency, and compatibility.
Among fusion strategies, model fusion via logit distillation has emerged as a flexible and efficient paradigm. It enables a single pivot model to absorb knowledge from multiple source models—often with diverse domains, sizes, or architectures—without increasing inference cost. A representative cross-tokenizer approach is ULD, which introduces a universal logit-distillation loss for aligning models with different tokenizers. Unlike traditional distillation, which transfers intermediate features or outputs, these methods align only the output logits using token-level objectives such as KL divergence or Wasserstein distance. However, token-level methods inherently treat each vocabulary dimension independently, overlooking semantic dependencies—the co-activation patterns and relational structures among tokens that underlie a model's reasoning process. This limits their ability to align models with divergent generation behaviors, particularly for tasks requiring multi-step reasoning or fine-grained relational inference.
The following figure illustrates this limitation. While token-level losses enforce dimension similarity, they fail to capture the structured dependencies among tokens. InfiGFusion addresses this by modeling logits as graphs, aligning not just distributions but also the interactions that reflect a model's internal reasoning.
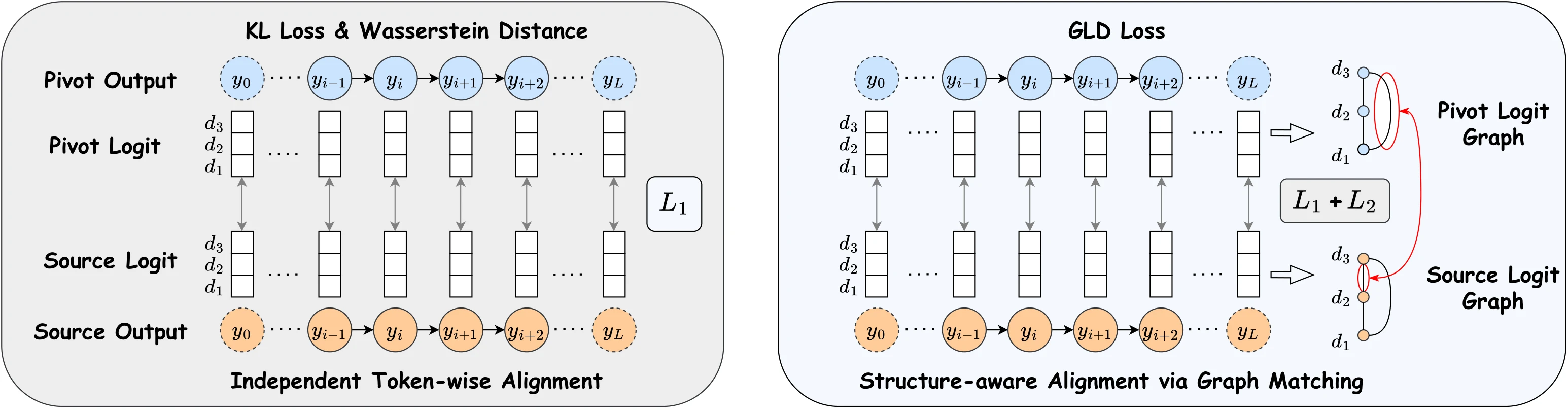
Figure 1: Token-level vs. Structure-aware Fusion. Given pivot and source logits of shape [L,3] (sequence length L, vocab size 3), token-level methods (left) align dimensions independently, ignoring token interactions. GLD (right) aggregates outer products into [3,3] co-activation graphs, capturing semantic dependencies via structure-aware graph alignment.
To address this challenge, we model semantic dependencies in the logit space using graph structures. Rather than treating token logits independently, we represent model outputs as feature-level graphs, where nodes correspond to token dimensions and edges capture their co-activation patterns across sequence positions. This representation reflects how a model internally organizes semantic relationships, beyond surface-level token probabilities, to support coherent reasoning and inference. Constructing such graphs from high-dimensional logits is nontrivial: vocabulary sizes are large, and most logits are near-zero, making full pairwise modeling inefficient and noisy. To mitigate this, we apply top- sparsification to retain salient dimensions, followed by inner-product similarity to define edge weights. This yields interpretable graphs that faithfully reflect model reasoning behaviors.
Building on this, we propose InfiGFusion, a semantic structure-aware fusion framework that distills knowledge from multiple source models by aligning their logit graphs. At its core is the Graph-on-Logits Distillation (GLD) loss, which captures semantic dependencies by aligning structure-level information between source and pivot models. Specifically, we employ the Gromov-Wasserstein (GW) distance to match graph structures. However, standard GW incurs complexity, making it impractical for large vocabularies. To address this, we design a closed-form approximation based on node aggregation and sorting-based matching, reducing the cost to . We further provide theoretical guarantees on the approximation error, ensuring alignment fidelity.
We validate InfiGFusion across diverse fusion scenarios, demonstrating consistent improvements over state-of-the-art methods. By explicitly modeling semantic dependencies through logit graph alignment, InfiGFusion excels in tasks involving multi-step reasoning, relational inference, and fine-grained alignment—scenarios where token-level objectives fall short. Extensive experiments on 11 benchmarks, including reasoning, mathematics, and coding, confirm its effectiveness in producing more capable fusion models.
Overall, our contributions can be summarized as follows:
- InfiGFusion is the first structure-aware fusion framework that models semantic dependencies via feature-level logit graphs and aligns them via a novel Graph-on-Logits Distillation loss.
- We propose a novel approximation to Gromov-Wasserstein distance, reducing complexity from to , with provable error bounds and rigorous theoretical analysis.
- Experiments on 11 benchmarks show that InfiGFusion consistently outperforms baselines, with significant gains on complex reasoning tasks (+35.6 on Multistep Arithmetic, +37.06 on Causal Judgement), demonstrating superior multi-step and relational inference.
Related Work
Collective LLM: To aggregate the capabilities of specialized LLMs, several strategies have been proposed. Prompt-based integration methods, such as Toolformer, ReAct, and HuggingGPT, guide LLMs to invoke tools or auxiliary models through natural language prompts. Multi-agent collaboration frameworks like ChatArena and AgentBench treat LLMs as interacting agents that debate or coordinate to improve reasoning. Model ensembling aggregates outputs via voting or reranking, but suffers from high inference cost. Mixture-of-Experts (MoE) models activate sparse expert subsets per query, offering scalability but introducing routing complexity. Parameter merging methods combine weights from fine-tuned models, but require architectural alignment. While these strategies explore different trade-offs between performance, efficiency, and flexibility, they generally assume the underlying models remain fixed. In contrast, we focus on knowledge fusion, where a pivot model learns from multiple sources during training.
Model Fusion via Knowledge Distillation: Traditional knowledge distillation (KD) transfers knowledge from a large teacher to a smaller student via features, logits, or output distributions, primarily for compression or acceleration. In contrast, model fusion via KD aims to integrate multiple source models—often with varying architectures, scales, and vocabularies—into a single target of similar size. Recent methods fuse multiple LLMs by aligning token distributions using KL divergence or Wasserstein distance. These approaches typically require vocabulary alignment and assume semantic compatibility at the token level. However, they overlook semantic dependencies among logit dimensions—i.e., how token probabilities interact under internal reasoning, which are crucial for preserving logical structure. Our work addresses this gap by introducing a structure-aware distillation objective that explicitly aligns semantic dependencies via graph alignment. Unlike prior methods, it avoids explicit vocabulary alignment by modeling logits as graphs, enabling robust, vocabulary-agnostic fusion across heterogeneous models while preserving reasoning structures.
Gromov-Wasserstein Distance: The Gromov-Wasserstein (GW) distance is a relational optimal transport metric for aligning distributions based on internal structural similarity. It has been widely used in graph comparison and structure-aware representation learning, especially when node correspondences are unknown. However, its standard formulation incurs complexity due to fourth-order interactions, rendering it impractical for large-scale logit graphs in LLMs. To mitigate this, prior works apply entropic regularization, Sinkhorn-based solvers, or low-rank projections. While effective for small graphs, these methods lack closed-form solutions and suffer from convergence instability, making them less suited for distillation over vocabulary-sized graphs (). Our method takes a non-iterative, sorting-based approach: it compresses each similarity matrix into node-level features and aligns them via sorted-based matching, reducing complexity to . Unlike prior approximations, it yields a differentiable, training-friendly loss with a provable approximation bound. To our knowledge, this is the first closed-form, theoretically guaranteed GW approximation tailored for aligning logit graphs in LLM fusion.
Method
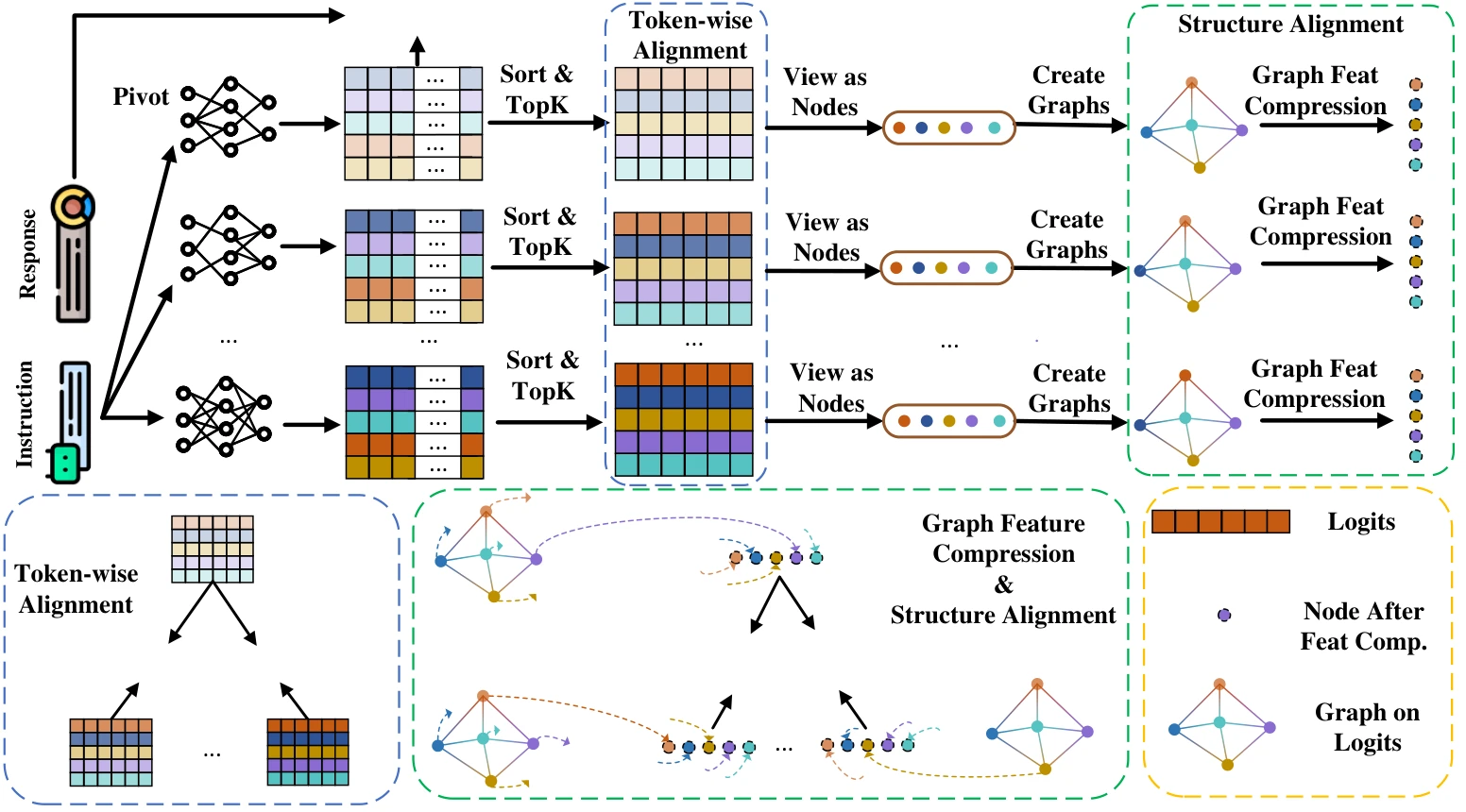
InfiGFusion fuses heterogeneous LLMs by distilling structured knowledge from multiple source models into a unified pivot model. Central to this process is the Graph-on-Logits Distillation (GLD) loss, which models logit vectors as feature-level graphs and aligns their structures across models.
To capture semantic dependencies, we adopt Gromov-Wasserstein distance for structure-level alignment between logit graphs. However, the standard GW incurs complexity, prohibitive for LLM-scale vocabularies (). We propose a sorting-based approximation that reduces this to by compressing graph structures into node-level features. Furthermore, we provide a provable error bound of , ensuring faithful and efficient graph alignment.
Figure 2: InfiGFusion framework. Given instruction-response pairs, source and pivot models produce logits, sparsified into feature-level graphs capturing semantic dependencies. We align graphs via an efficient Gromov-Wasserstein approximation (GLD), reducing complexity from O(n^4) to O(n log n). The overall objective combines structure-aware distillation (GLD) with token-level distillation (ULD) and supervised signals (SFT) for robust fusion.
Overview of InfiGFusion
InfiGFusion integrates knowledge from diverse source models into a unified pivot model , enhancing reasoning capabilities without increasing inference cost.
Given an instruction-response dataset , is trained to align with both human supervision and source model behaviors via two complementary objectives: (i) Universal Logit Distillation (ULD): a coarse token-level alignment combining supervised fine-tuning (SFT) and a sorting-based Wasserstein-1 approximation; (ii) Graph-on-Logits Distillation (GLD): a structure-aware objective aligning relational dependencies in logit space. The overall loss is:
where ULD ensures distributional alignment and GLD captures fine-grained reasoning structures. For token-level ULD, we adopt the linear-time Wasserstein-1 approximation, which compare the logit distributions between pivot model and source models :
where denotes sorting. This provides an efficient coarse alignment signal, complementing GLD's structural matching.
Dynamic Sparse Graph Construction
To capture structural dependencies among logit dimensions while avoiding the cost of full modeling ( is the vocabulary size for each model), we adopt a two-stage strategy: top- sparsification followed by dynamic graph construction.
Top- Logit Sparsification. Given a logit tensor , we extract the top- logits for each position to obtain , with . We then unify the top- dimensions across tokens to obtain a consistent -dimensional representation per sample.
Dynamic Graph Construction. To model the interdependencies among logit dimensions, graph construction can generally follow two paradigms: (i) token-wise similarity across the sequence, or (ii) feature-wise similarity among logit dimensions. The former focuses on token interactions, while the latter captures intrinsic correlations between semantic dimensions. In this work, we adopt the feature-wise approach, as it empirically yields better alignment performance and more effectively preserves structural information. Specifically, for each sample , we construct a graph over the reduced logits , where each node corresponds to a selected logit dimension. The adjacency matrix is defined via dot-product similarity across the sequence:
This construction approximates cosine similarity after normalization and is applied to both pivot and source models at every training step, resulting in dynamic, data-dependent graphs that evolve with model predictions.
Efficient Approximation Algorithm
Directly applying Gromov-Wasserstein (GW) distance for structure-level alignment incurs complexity, which is infeasible for LLM-scale graphs. We propose an efficient approximation by summarizing graph structures into node-level features and aligning them via sorting-based matching, reducing complexity to . This method maintains alignment fidelity with a provable error bound of .
Given intra-graph similarity matrices from source and pivot models, the squared GW distance is defined as:
Despite its expressiveness, the GW objective requires complexity due to its fourth-order tensor form, making it impractical for large logits ( are the vocabulary sizes). To address this, we derive a closed-form approximation by compressing the graph structure into scalar features.
Graph Feature Compression. Our key insight is that the structure of each similarity matrix and can be summarized using scalar node-level features, where are vocabulary size. Specifically, we compute degree-style features:
which captures the overall importance or connectivity of each logit dimension in the graph. This reduces the original structure to two vectors in .
Separable Relaxation. Substituting these features into the original objective yields a simplified, separable form:
where symmetry is assumed across and . This relaxation significantly lowers computational cost. The error is theoretically bounded:
Proposition 1 (Approximation Error Bound). Let and be the similarity matrices derived from logit self-inner products and row-normalized such that and . Then the absolute error between the exact and approximated GW distances satisfies:
In practice, the size of is more than . This bound guarantees the error decays as , enabling scalable use in large-vocabulary settings.
Sorting-Based Matching. To avoid solving for the optimal transport plan explicitly, we take a direct strategy like ULD that adopts a deterministic transport strategy based on sorting. Let be the descending-sorted versions of and . We construct a matching that aligns the -th largest entry of to the -th largest entry of :
This effectively reduces the original optimization to an sorting-based assignment.
Stability Analysis. Beyond efficiency, our approximation improves training stability. We compare the Lipschitz constants of common alignment losses:
Proposition 2 (Lipschitz Constants Comparison). We have the following relationship between the Lipschitz constants () for the Gromov-Wasserstein, Wasserstein, and KL losses:
for vocabulary size and logit range , which means the GW-guided training models have tighter generalization bounds.
The logit range is usually smaller than 120 for 14B LLMs. For example, with vocabulary size , is observed in the range of . This suggests GW-based alignment yields the lowest sensitivity to perturbations, contributing to improved generalization and stable training.
Unified GLD Loss
To support multi-source fusion, we extend the GLD loss into a unified formulation. For each source model , we compute a structure-aware alignment loss with respect to the pivot model and aggregate all source contributions:
where and denote the similarity matrices of the source and pivot graphs, respectively.
This unified objective enables efficient and scalable distillation from multiple source models, while preserving both semantic and relational structures across models.
Experiments
We evaluate InfiGFusion on large-scale LLM fusion, focusing on integrating models with diverse architectures and reasoning styles while maintaining inference efficiency. Our experiments verify that GLD enables faithful and effective fusion beyond token-level objectives. InfiGFusion outperforms state-of-the-art fusion methods and strong open-source baselines, with significant improvements in multi-step reasoning and relational inference.
Experimental Setup
Datasets. We construct a novel multi-task training dataset comprising 130k examples across general reasoning, mathematics, and coding. (i) The 52K general data are sourced from Infinity-Instruct. (ii) Our mathematical dataset comprises 39k pairs of math questions and corresponding answers. The questions are sourced from the NuminaMath_1.5 dataset, while the answers are distilled from the DeepSeek-R1-671B model. NuminaMath_1.5 represents the second iteration of the widely acclaimed NuminaMath dataset. It offers high-quality data for competition-level mathematical problems across various domains, including Algebra, Geometry, Combinatorics, Calculus, Inequalities, Logic and Puzzles, and Number Theory. (iii) In the code generation domain, we utilized the KodCode-V1-SFT-R1 dataset, which contains approximately 268k samples. Each sample was fed into our pivot model, which was prompted to generate 5 random responses per input. The generated outputs were then passed through a sandbox-based evaluation system. For each sample, if at least one of the five responses failed, the sample was flagged for further consideration. From these flagged samples, we filtered and selected 39k high-quality examples for further distillation.
| Types | General | Math | Code |
|---|---|---|---|
| Dataset | Infinity-Instruct | NuminaMath-1.5 | KodCode-V1-SFT-R1 |
| Original Size | 1.4M | 1.4M | 268k |
| Filtered Size | 52K | 39K | 39K |
Models and Baselines. We fuse three source models: Qwen2.5-14B, Qwen2.5-Coder-14B, and Mistral-24B, into a Phi-4 pivot model. Fusion baselines include MiniLogit, InfiFusion, FuseLLM, and FuseChat.
Evaluation. We assess fusion performance on 11 benchmarks spanning reasoning (BBH, ARC-C, MMLU), mathematics (GSM8K, Math, TheoremQA), coding (MBPP, HumanEval), text reasoning (DROP, HellaSwag), and instruction following (IFEval).
Main Results
| Models | GSM8K | MATH | ThQA | MBPP | HEval | BBH | ARC | MMLU | IFEval | DROP | HS | Avg | Size | GPU Hour |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pivot Model | ||||||||||||||
| Phi-4 | 87.41 | 80.04 | 51.12 | 70.8 | 83.54 | 68.84 | 93.9 | 85.62 | 77.34 | 88.67 | 87.62 | 79.54 | 14B | ~1.0M |
| Source Models | ||||||||||||||
| Qwen2.5-Instruct | 91.13 | 78.16 | 47.25 | 81.70 | 83.54 | 77.59 | 92.20 | 80.22 | 85.01 | 85.56 | 88.28 | 80.97 | 14B | ~1.8M |
| Mistral-Small | 92.42 | 69.84 | 48.50 | 68.80 | 84.15 | 81.59 | 91.86 | 81.69 | 82.25 | 86.52 | 91.84 | 79.95 | 24B | ~1.6M |
| Qwen2.5-Coder | 89.16 | 74.18 | 38.88 | 85.40 | 90.90 | 75.40 | 89.49 | 75.08 | 74.70 | 84.34 | 79.83 | 77.94 | 14B | ~1.8M |
| SFT | ||||||||||||||
| Pivot-SFT | 89.99 | 82.96 | 54.50 | 77.86 | 87.80 | 67.23 | 93.56 | 86.21 | 77.70 | 89.44 | 87.76 | 81.36 | 14B | 120 |
| Model Fusion via Distillation | ||||||||||||||
| MiniLogit | 89.80 | 79.78 | 46.36 | 78.49 | 85.44 | 82.68 | 92.19 | 84.58 | 79.36 | 88.56 | 88.25 | 81.43 | 14B | 220 |
| FuseLLM | 90.24 | 80.25 | 53.52 | 79.28 | 84.00 | 77.62 | 92.08 | 83.92 | 78.56 | 88.74 | 87.81 | 81.46 | 14B | 225 |
| FuseChat | 91.21 | 77.52 | 51.88 | 81.80 | 84.15 | 83.37 | 93.56 | 84.23 | 78.90 | 89.23 | 87.42 | 82.12 | 14B | 650 |
| InfiFusion | 90.07 | 80.94 | 54.62 | 79.63 | 84.72 | 80.94 | 94.24 | 85.81 | 76.02 | 89.27 | 87.91 | 82.20 | 14B | 160 |
| InfiGFusion | 90.45 | 81.92 | 55.38 | 85.2 | 86.00 | 85.62 | 94.58 | 85.24 | 80.22 | 89.62 | 88.22 | 83.85 | 14B | 195 |
The table above summarizes the performance of InfiGFusion across eleven benchmarks, compared with the pivot model, source models, and representative model fusion methods.
Comparison with Pivot and Source Models. InfiGFusion consistently outperforms both the pivot model and source models in overall performance. Compared to the pivot model, it achieves a significant improvement (+2.53 avg), particularly on complex reasoning benchmarks such as BBH, ARC, and MMLU, where semantic richness and multi-step inference are crucial. For instance, InfiGFusion surpasses the pivot by +16.7 on BBH, demonstrating its ability to aggregate diverse reasoning styles beyond single-source capabilities. Compared to source models, InfiGFusion effectively integrates complementary strengths. While individual source models excel in isolated tasks (e.g., Mistral-Small on BBH, Qwen2.5-Coder on HEval), they struggle with generalization across domains. InfiGFusion surpasses these models with a more balanced performance, avoiding their trade-offs and consolidating knowledge into a unified pivot.
Comparison with Model Fusion Baselines. Against existing fusion methods (MiniLogit, FuseLLM, FuseChat), InfiGFusion exhibits superior fusion quality. Notably, while other distillation methods provide moderate improvements over the pivot, they often suffer from degraded performance in high-dependency tasks (e.g., logical reasoning, multi-condition alignment). InfiGFusion consistently delivers better results on structurally challenging tasks, indicating its advantage in preserving inter-token dependencies during fusion. Furthermore, compared to simpler fusion objectives, the structure-aware GLD loss of InfiGFusion yields better alignment without sacrificing robustness.
Efficiency and Resource Usage. In terms of computational cost, InfiGFusion maintains competitive efficiency. Despite introducing structure-aware alignment, its GPU hours remain modest (195 GPU hours), substantially lower than multi-step fusion pipelines like FuseChat (650 GPU hours). Model size remains identical to the pivot (14B), ensuring no additional inference overhead.
Complex Reasoning Performance
We evaluate InfiGFusion on 18 reasoning datasets spanning BBH and MMLU, covering multi-step logic, structural dependencies, and fine-grained semantic alignment, as shown in the following table. These tasks are known to challenge token-level fusion methods due to their complex reasoning path.
| Reasoning Models | Qwen2.5-Instruct | Mistral | DeepSeek-R1-Distill-Qwen | Phi4 | Phi4 (SFT) | InfiGFusion |
|---|---|---|---|---|---|---|
| Models Size | 14B | 24B | 14B | 14B | 14B | 14B |
| Abstract Algebra | 73 | 65 | 85 | 82 | 86 (+4.0) | 88 (+6.0) |
| Marketing | 90.17 | 92.31 | 89.32 | 92.74 | 92.74 (+0.0) | 95.3 (+2.56) |
| International Law | 81.82 | 81.82 | 82.64 | 91.74 | 90.91 (-0.83) | 90.91 (-0.83) |
| Moral Scenarios | 71.96 | 68.6 | 73.41 | 75.75 | 74.75 (-1.0) | 73.97 (-1.78) |
| Virology | 52.41 | 49.4 | 54.22 | 53.01 | 53.61 (+0.6) | 54.22 (+1.21) |
| Formal Logic | 68.25 | 66.67 | 91.27 | 77.78 | 78.57 (+0.79) | 74.6 (-3.18) |
| Security Studies | 77.96 | 78.78 | 78.37 | 77.14 | 79.59 (+2.45) | 81.22 (+4.08) |
| logical_fallacies | 85.28 | 84.66 | 85.28 | 86.5 | 87.73 (+1.23) | 87.73 (+1.23) |
| Ruin Names | 82.8 | 76.8 | 39.6 | 88.8 | 88.0 (-0.8) | 88.4 (-0.4) |
| Tracking 7 Objects | 80.4 | 96.4 | 80.8 | 94.4 | 90.0 (-4.4) | 96.8 (+2.4) |
| Tracking 5 Objects | 79.2 | 99.2 | 82.8 | 96.8 | 95.6 (-1.2) | 96.8 (+0.0) |
| Logical Deduction 3 | 97.6 | 98.8 | 83.2 | 98.4 | 96.4 (-2.0) | 97.6 (-0.8) |
| Logical Deduction 5 | 80.4 | 82 | 86 | 85.6 | 92.4 (+6.8) | 94 (+8.4) |
| Logical Deduction 7 | 68.8 | 62.8 | 83.2 | 88.4 | 88.8 (+0.4) | 89.2 (+0.8) |
| Colored Objects | 93.6 | 90 | 87.6 | 96.4 | 96.8 (+0.4) | 96.4 (+0.0) |
| Multistep Arithmetic | 96.4 | 93.2 | 81.6 | 64 | 62 (-2.0) | 99.6 (+35.6) |
| Dyck Languages | 35.6 | 37.2 | 9.6 | 11.2 | 13.2 (+2.0) | 40.0 (+28.8) |
| Causal Judgement | 43.85 | 68.98 | 45.35 | 32.99 | 35.83 (+2.84) | 70.05 (+37.06) |
| Avg. 18 Tasks | 75.53 | 77.37 | 73.29 | 77.43 | 77.94 (+0.51) | 84.16 (+6.73) |
Improved Reasoning over SFT. Compared to Phi4-14B after supervised fine-tuning (SFT), InfiGFusion delivers consistent gains, boosting the average accuracy from 77.94% to 83.79%. Notable improvements are observed in tasks demanding complex relational reasoning: Multistep Arithmetic (+34.8%) and Causal Judgement (+34.39%). This demonstrates InfiGFusion's ability to enhance multi-hop inference and causal understanding by explicitly modeling semantic dependencies.
Structural Alignment Benefits. InfiGFusion excels in Tracking Shuffled Objects and Logical Deduction tasks, where aligning token relations is critical. For instance, it surpasses Phi4-14B SFT on Logical Deduction Five Objects (+1.6%) and Seven Objects (+0.4%), showcasing robust structure-level fusion beyond token alignment.
Preserving Pivot Strength. InfiGFusion maintains competitive performance in knowledge-centric tasks like International Law and Ruin Names, matching or slightly improving upon SFT baselines. This indicates that InfiGFusion not only integrates external model knowledge but also preserves the pivot model's original strengths. These results confirm that InfiGFusion's structure-aware fusion consistently enhances reasoning capabilities compared to token-level methods.
Ablation Study
Effect of Source Model Diversity. The following table evaluates the effect of fusing different source models. Individually, Qwen-Coder (Qc), Qwen-Instruct (Qi), and Mistral (M) each provide moderate gains, reflecting their domain-specific strengths. Notably, combinations such as Qi-M further amplify reasoning (+3.57), math (+3.06), and coding (+8.22) performance, demonstrating that complementary inductive biases from different models enhance the pivot model. InfiGFusion achieves the best results (+2.53 avg), confirming that our framework effectively consolidates diverse reasoning behaviors into a unified model.
| Model | Reasoning | Math | Coding | Avg |
|---|---|---|---|---|
| Pivot: Phi4 | 81.43 | 72.86 | 77.17 | 79.54 |
| Qc | 84.39 (+2.96) | 74.18 (+1.32) | 86.1 (+8.63) | 83.20 (+3.66) |
| Qi | 86.03 (+4.60) | 74.08 (+1.22) | 84.89 (+7.72) | 83.52 (+3.98) |
| M | 84.50 (+3.07) | 75.77 (+2.91) | 85.8 (+8.63) | 83.62 (+4.08) |
| Qc-M | 84.89 (+3.46) | 74.18 (+1.32) | 86.09 (+8.92) | 83.54 (+4.00) |
| Qi-M | 85.00 (+3.57) | 75.92 (+3.06) | 85.39 (+8.22) | 83.72 (+4.18) |
| InfiGFusion | 87.06 (+5.63) | 74.74 (+1.88) | 85.6 (+8.43) | 83.85 (+2.53) |
Effect of Loss Components. The following table analyzes our loss design. Removing ULD (w/o ULD) leads to a significant drop (-1.52 avg), particularly in reasoning (-1.8), indicating that coarse-grained token-level alignment is crucial for providing a reliable starting point. ULD narrows large distribution mismatches, effectively preparing the model for the finer-grained structural alignment performed by GLD. Excluding GLD (w/o GLD), on the other hand, yields a smaller overall decline (-0.69 avg), but reasoning performance still drops notably (-1.36). This highlights that while ULD handles first-order token matching, it lacks the capacity to capture higher-order semantic dependencies. When combined, ULD and GLD form a synergistic alignment mechanism: ULD aligns distributions coarsely and stabilizes optimization, while GLD refines alignment by enforcing consistency in the relational structure of logits. The empirical results validate this design, with the full loss achieving the best performance. All ablation studies are tested in the Top- setting.
| Component | Reasoning | Math | Coding | Avg |
|---|---|---|---|---|
| GLD + ULD | 87.06 | 74.74 | 85.6 | 83.85 |
| w/o ULD | 85.26 (-1.8) | 73.28 (-1.46) | 85.28 (-0.32) | 82.33 (-1.52) |
| w/o GLD | 85.70 (-1.36) | 75.21 (+0.47) | 85.18 (-0.42) | 83.16 (-0.69) |
Effect of Top-
InfiGFusion sparsifies logits by retaining top- token dimensions before graph construction, selecting the most salient indices per sequence position. This inductive bias suppresses noisy activations and emphasizes meaningful token dependencies, serving as the foundation for graph-based semantic alignment. We evaluate Top- and report the results below. Increasing from 5 to 10 brings notable gains across all tasks (Avg +0.54), as larger captures richer token interactions essential for semantic graph construction. However, further increasing beyond 10 yields diminishing returns and even slight degradations, particularly in reasoning (-0.49 from Top10 to Top30). This suggests that excessive low-confidence tokens introduce spurious edges, diluting graph discriminability. The observed trend aligns with the heavy-tailed nature of LLM logits, where only a small subset of token dimensions are informative. Overall, Top-10 achieves the best trade-off, balancing informative graph structure and computational efficiency.
| Top-k | Reasoning | Math | Coding | Avg |
|---|---|---|---|---|
| 5 | 87.03 | 74.38 | 84.42 | 82.08 |
| 10 | 87.55 | 75.92 | 85.39 | 82.62 |
| 15 | 87.37 | 75.47 | 85.35 | 82.49 |
| 20 | 87.22 | 75.03 | 85.48 | 82.41 |
| 25 | 87.12 | 74.58 | 85.71 | 82.20 |
| 30 | 87.06 | 74.74 | 85.6 | 82.07 |
Case Study
To illustrate InfiGFusion's strengths beyond token-level alignment, we analyze representative cases, comparing outputs from a standard SFT-tuned model (Phi4) and our InfiGFusion model. The selected examples highlight InfiGFusion's superior reasoning in multi-step causality and relational inference.
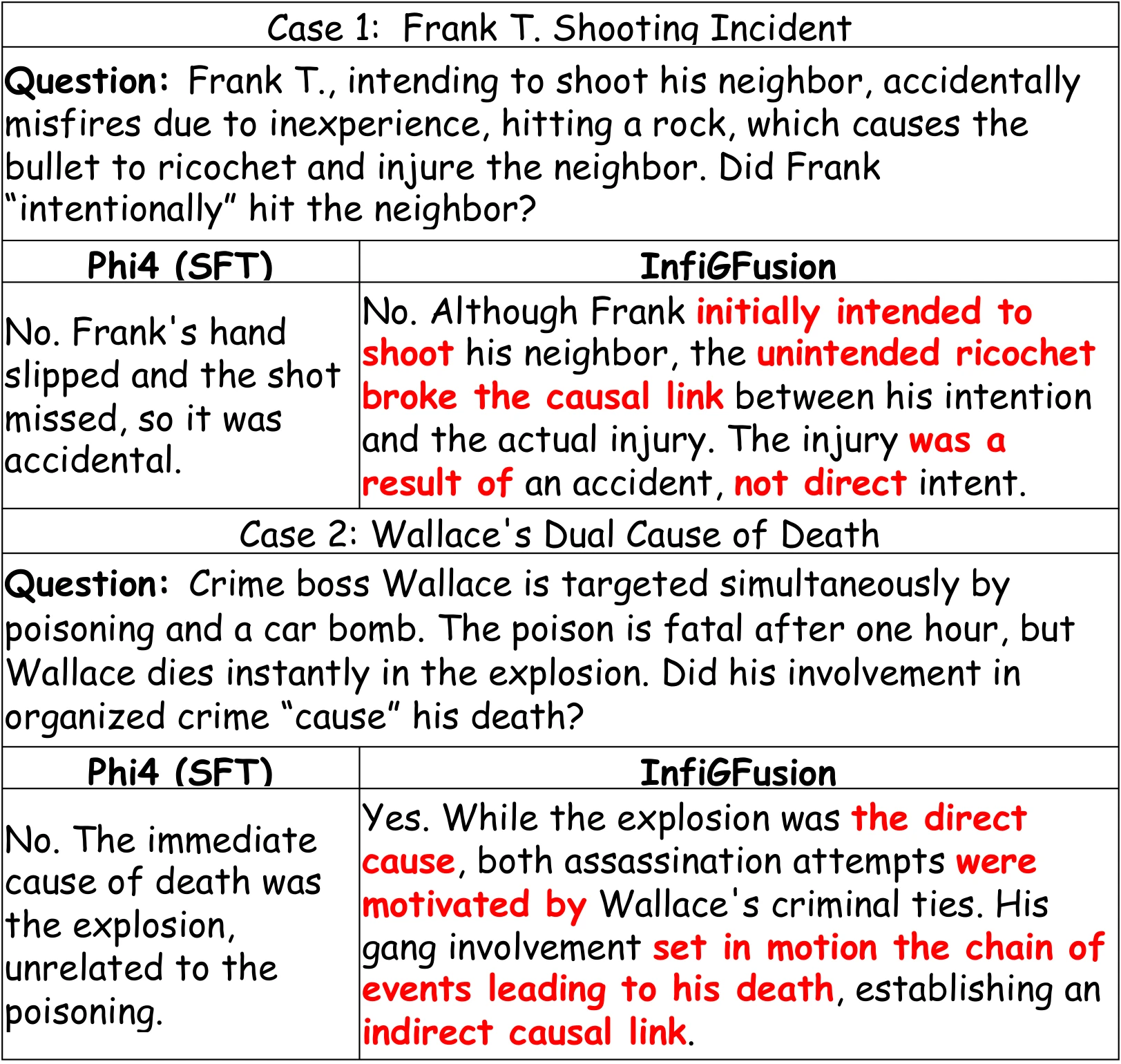
Figure 3: Case study.
Case 1: Frank T. Shooting Incident. While both models predict "No," InfiGFusion performs a deeper step-by-step causality analysis. It explicitly identifies the causal chain's disruption—distinguishing between "intent," "misfire," and "accidental result"—showcasing robust multi-step causality disambiguation capabilities.
Case 2: Wallace's Dual Cause of Death. Unlike Phi4's surface-level judgment, InfiGFusion reasons through the latent causal structure, identifying "organized crime" as a distal cause. This reflects its strength in relational and indirect causality inference, where it effectively models complex event chains and upstream dependencies.
These cases demonstrate that InfiGFusion excels at: (i) Multi-step inference: Decomposing complex causal chains into interpretable reasoning steps. (ii) Relational causality reasoning: Capturing indirect and upstream causal factors often missed by SFT models. (iii) Fine-grained disambiguation: Distinguishing intent, action, and outcome with structured alignment of reasoning behaviors.
Analysis of the GW Approximation
In addition to the main results, we also conducted some experiments to analyze our proposed Gromov-Wasserstein approximation. It compares the quality of GW estimation in a simple simulated scenario. For example, by obtaining samples from two Gaussian distributions, and comparing the value of exact GW, sinkhorn-based approximation, and our proposed approximation. While our experiments demonstrate that the approximation is suitable as a training objective, it would be interesting to also understand its behavior as GW estimator.
Experiment setup: For each , we sample points from and , build their Euclidean distance matrices, and compute: (i) Exact GW and Sinkhorn GW via ot.gromov.gromov_wasserstein2(..., loss='square_loss'); (ii) Approx GW via our sorting-based closed-form. Each configuration is repeated to report meanstd. Approx RE quantifies the approximation accuracy relative to the exact GW: (meanstd over 5 seeds). In this symmetric Gaussian setting, Exact and Sinkhorn GW coincide to our reported precision (even with ), evidencing the high accuracy of the Sinkhorn estimator here.
| Exact&&Sinkhorn GW | Approx GW | Approx RE (±std) | Time Exact (s) | Time Sink (s) | Time Approx (s) | |
|---|---|---|---|---|---|---|
| 50 | 0.4815 ± 0.0452 | 0.1978 ± 0.0207 | 0.5888 ± 0.0242 | 0.0171 ± 0.0207 | 0.0027 ± 0.0005 | 0.0004 ± 0.0004 |
| 100 | 0.3247 ± 0.0297 | 0.1261 ± 0.0217 | 0.6048 ± 0.0907 | 0.0072 ± 0.0008 | 0.0070 ± 0.0005 | 0.0001 ± 0.0000 |
| 200 | 0.2033 ± 0.0088 | 0.0973 ± 0.0125 | 0.5230 ± 0.0426 | 0.1390 ± 0.0377 | 0.0983 ± 0.0033 | 0.0359 ± 0.0305 |
| 500 | 0.1131 ± 0.0050 | 0.0587 ± 0.0143 | 0.4850 ± 0.1121 | 0.4405 ± 0.1337 | 0.4815 ± 0.0904 | 0.0607 ± 0.0353 |
| 1000 | 0.0764 ± 0.0011 | 0.0387 ± 0.0133 | 0.4921 ± 0.1785 | 2.3631 ± 0.4981 | 2.2456 ± 0.4085 | 0.1238 ± 0.0399 |
| 1500 | 0.0621 ± 0.0028 | 0.0308 ± 0.0016 | 0.5031 ± 0.0398 | 12.7151 ± 4.1182 | 9.1998 ± 2.1952 | 0.0982 ± 0.0015 |
| 2000 | 0.0496 ± 0.0028 | 0.0294 ± 0.0058 | 0.3995 ± 0.1453 | 20.1236 ± 5.0250 | 19.8941 ± 8.1827 | 0.0411 ± 0.0424 |
| 2500 | 0.0455 ± 0.0008 | 0.0305 ± 0.0075 | 0.3285 ± 0.1712 | 20.9198 ± 5.6782 | 30.1367 ± 3.1038 | 0.0026 ± 0.0014 |
| 3000 | 0.0404 ± 0.0002 | 0.0324 ± 0.0141 | 0.3941 ± 0.0767 | 52.8898 ± 9.2735 | 53.5049 ± 12.4434 | 0.2408 ± 0.2562 |
Results and analysis: Each setting is repeated 5 times with different seeds; we report mean±std. Across all sizes, Sinkhorn GW matches Exact GW to our reported precision (RE ≈ 0), hence we merge them into a single column in the table above. Our Approx GW exhibits decreasing relative error as grows (from ≈ 0.59 at down to ≈ 0.39 at ), consistent with the behavior. In terms of runtime, Exact/Sinkhorn scale poorly and rapidly become impractical beyond a few hundred points (already seconds at and tens of seconds by on our machine), whereas Approx GW remains below ~0.3 s even at , demonstrating its scalability.
Conclusion
In this work, we propose InfiGFusion, a structure-aware fusion framework that explicitly models semantic dependencies among logits through a novel Graph-on-Logits Distillation (GLD) loss. By leveraging logit graph representations and an efficient Gromov-Wasserstein approximation, InfiGFusion enables the integration of heterogeneous LLMs without increasing inference cost. Extensive experiments on 11 benchmarks demonstrate that InfiGFusion consistently outperforms state-of-the-art fusion methods and baselines. In particular, it achieves notable gains in multi-step and relational reasoning tasks, such as +35.6 on Multistep Arithmetic and +37.06 on Causal Judgement over SFT models. It highlights the importance of structure-preserving alignment for effective model fusion in complex reasoning tasks, which is a promising direction for advancing collective LLM.
Limitations
While InfiGFusion demonstrates clear advantages in tasks involving multi-step reasoning, causal inference, and relational alignment, its performance shows limitations in scenarios dominated by literal token matching or factual recall. For tasks where the correct answer is encoded by a few dominant logit dimensions (e.g., factoid QA), the added structural alignment of GLD brings marginal benefits and may even introduce noise from irrelevant dependencies. Moreover, when source models present conflicting factual knowledge, InfiGFusion focuses on preserving relational consistency but lacks explicit mechanisms for factual conflict resolution, sometimes amplifying semantic ambiguities. These limitations reflect inherent trade-offs in structure-aware fusion and motivate future work on adaptive dependency modeling and source reliability estimation.
Our model is available at https://huggingface.co/InfiX-ai/InfiGFusion-14B.
BibTeX
@article{wang2025infigfusion,
title={InfiGFusion: Graph-on-Logits Distillation via Efficient Gromov-Wasserstein for Model Fusion},
author={Wang, Yuanyi and Yan, Zhaoyi and Zhang, Yiming and Zhou, Qi and Gu, Yanggan and Wu, Fei and Yang, Hongxia},
journal={arXiv preprint arXiv:2505.13893},
year={2025}
}